Success Story: Migrating from AWS EMR to Kubernetes

This article was originally published on Medium - Empathy.co
Motivation
In December 2020, our Spark workloads orchestration using EMR had become increasingly complex. The Step Function flow orchestrating different EMR clusters was becoming difficult to manage. This led to our Platform Engineering team proposing a migration to Kubernetes in January 2021.
Core Migration Objectives
Our replatforming fundamentals focused on three key areas:
1. Operability
- Scalability
- Reliability
- Portability
2. Observability
- Metrics
- Logging
3. Efficiency
- Performance
- Cost-effectiveness
Over a period of six months, three teams were focused exclusively on replatforming those Spark workloads to Kubernetes. The main goal was to complete the migration without focusing on performance or any more enhancements. However, for business purposes, there were some improvements in some jobs and some new Spark jobs were added. Six months later, all the jobs have been migrated to Kubernetes and EMR was decommissioned successfully.
Success Criteria and Results
Operability Improvements
Scalability
EMR Limitations:
- Restricted instance type compatibility
- Slow autoscaling (≈7 minutes for task manager scaling)
- Limited flexibility
Kubernetes Advantages:
- Support for most AWS instance types
- Rapid autoscaling (≈1 minute for new instances)
- Flexible node pools with taints/tolerations
Reliability
EMR Challenges:
- Unstable spot instance behavior
- Complex jar distribution
- Cloud provider version dependencies
Kubernetes Solutions:
- More stable spot instance performance
- Docker image-based distribution
- Cloud provider independence
Portability
EMR Dependencies:
- AWS Services Required:
- Step Functions
- Lambda
- CloudWatch
- API Gateway
- CloudFormation
- S3
Kubernetes Stack:
- Core Components:
- Spark Operator
- Argo Workflows
- ArgoCD
- Docker Registry
- S3 (only for persistence)
Observability Improvements
Metrics
In both cases, Push-gateway was used to allow batch jobs to expose their metrics to Prometheus, while Grafana was used to review Dashboards. Some differences:
In the EMR scenario, the monitoring solution had some caveats regarding workflow complexity that created friction between teams because of the lack of standardisation. With the Kubernetes solution, Platform Engineering provides an opinionated workflow that helps to easily add metrics to Prometheus and dashboards to Grafana.
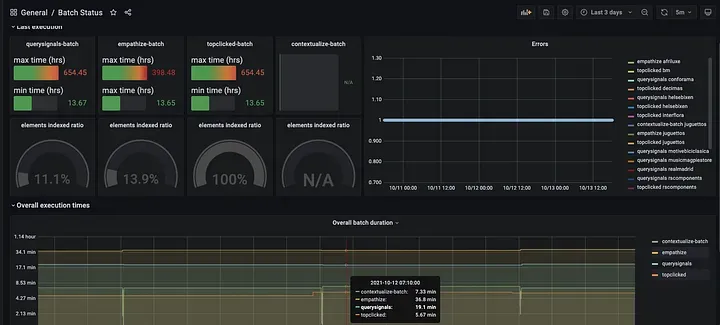
With EMR, it was available only during the cluster execution. With Kubernetes, it has been launched with S3 persistence, therefore the historical data is available after cluster termination.
Logging
Some years ago, Empathy couldn’t find any open source solution that fit well enough with the requirements. The usual ELK stack showed some performance issues on Logstash, so the decision was taken to create an in-house log-parser to send metrics to Elasticsearch until some open source tool fit the requirements. The in-house solution had dependencies on a custom service running on each instance: AWS Kinesis and AWS Lambda. Hence, the solution was always tied to AWS. Last year, the use of EFK started increasing in the community and with the migration to Kubernetes, the decision was to adopt this logging stack and retire the in-house log solution. The logging-operator from Banzai meets the requirements, and it’s been happily deployed as the logging solution.
Now, spark logs can be retrieved using the kubectl logs command and from a Kibana UI, where each team can create/customise their logging flow.
The main achievement here was being able to get rid of the in-house solution whilst also improving team autonomy to customise their logging flow easily.
Efficiency
### Performance
Once the migration had been completed, it was enough to compare with the EMR solution to review how well the job had been performed.
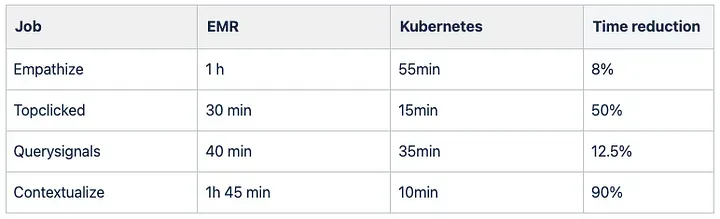
### Cost-effectiveness
One motivation to move to Kubernetes was to reduce the cost; as you know, EMR has a fee on AWS, but EKS does too. The EKS fee is lower than the EMR fee, although the EKS fee is shared between all the workloads running on the cluster. Let’s review if the goal has been accomplished by reviewing one lower environment:
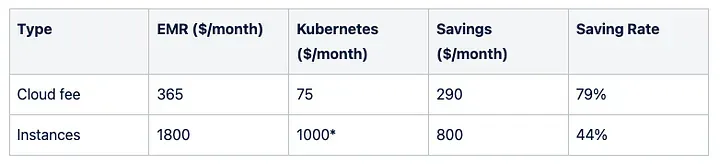
On top of this, there is an increase in the number of jobs launched:

Summary
The conclusions are the following:
- Operability
- Scalability: Faster instance provision.
- Reliability: Spot instances have a more reliable behaviour than using Spot on EMR. Docker image distribution and Spark version independence from a cloud provider.
- Portability: Docker image providing a better distribution flow, avoid too many dependencies from AWS, and adopt open source approach.
- Observability
- Metrics: Clear workflow definition.
- Logging: EFK open source adoption and provide more autonomy to the teams.
- Efficiency
- Performance: Better performance.
- Cost-effectiveness: Reduce cost as well as increase Spark usage.
Future
- Operability
- Deployment with enterprise customers to replace Google Dataproc
- Performance tuning
- Observability
- Custom metrics for Grafana dashboards
- Alerting on failed jobs
- Tracing
- Efficiency
- Adopt spot instances on Data jobs
- Allocate cost to Kubernetes workloads to provide a faster business feedback
- Optimise usage, fine-tuning underutilisation resources
- Adopt spot instances on Data jobs
This has been a long article and we’ve learned a lot along the way. I hope our learnings will help you to become more cloud-agnostic.
Resources
About the Author
I'm a Platform Engineer Architect specializing in cloud-native technologies and engineering leadership. With extensive experience in both Apache Spark and Kubernetes, I focus on building scalable, cloud-agnostic data processing solutions.


