Running Apache Spark on Kubernetes: A Cloud-Agnostic Approach

This article was originally published on Medium - Empathy.co
As organizations scale their data processing needs, moving away from cloud provider-specific solutions becomes increasingly important. In this article, I'll share my experience deploying Apache Spark on Kubernetes, including challenges faced and solutions implemented.
The Challenge of Cloud Provider Dependencies
When running Spark in production, organizations typically rely on cloud-specific solutions:
- AWS: EMR
- GCP: Dataproc
- Azure: HDInsight
While these services offer simplicity, they raise several critical questions:
- How do you orchestrate jobs effectively?
- What's the best way to distribute Spark jobs?
- How do you handle nightly job scheduling?
- Where should job configurations live?
- How can you propagate changes efficiently?
- Is job definition reuse possible?
- Can jobs be referenced through code?
- How do you support local development?
Why Kubernetes for Apache Spark?
Running Spark on Kubernetes offers several compelling benefits:
- Scalability: The new solution should be scalable for any needs.
- Reliability: The new solution should monitor compute nodes and automatically terminate and replace instances in case of failure.
- Portability: The new solution should be deployable in any cloud solution, avoiding dependency on a particular cloud provider. Overall, this approach saves time in thinking about orchestrating, distributing, and scheduling Spark jobs with the different cloud service providers.
- Cost-effectiveness: You don’t need the cloud provider, so you can save on these costs.
- Monitoring: The new solution should include ad-hoc monitoring.
- K8s ecosystem: Uses common ecosystem as with other workloads and offers continuous deployment, RBAC, dedicated node-pools, autoscaling, etc.
The benefits are the same as the solution for Apache Flink running on Kubernetes, as I explored in my previous article.
Apache Spark on Kubernetes
Apache Spark is a unified analytics engine for big data processing, particularly handy for distributed processing. Spark is used for machine learning and is currently one of the biggest trends in technology.
Apache Spark Architecture
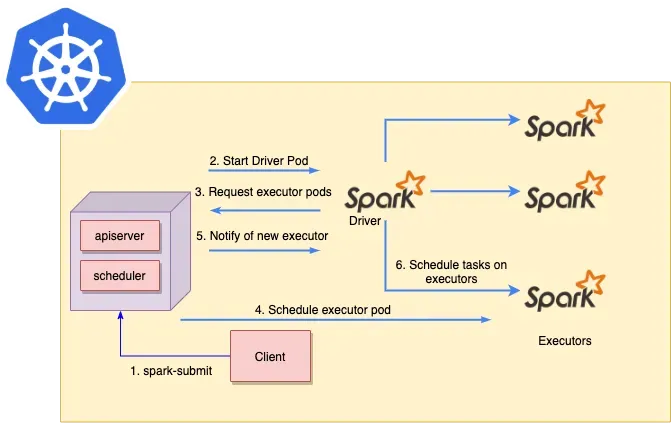
- Spark Submit sends request to Kubernetes API
- K8s schedules Spark Driver pod
- Driver requests executor pods
- K8s schedules executor pods
- K8s notifies Driver of ready executors
- Driver schedules tasks on executors
You can schedule a Spark Application using Spark Submit (vanilla way) or using Spark Operator. ### Spark Submit Spark Submit is a script used to submit a Spark Application and launch the application on the Spark cluster. Some nice features include:
- Kubernetes version: Not dependent on Kubernetes version.
- Native Spark: It’s included in the Spark image.
- Non-declarative setup: Need to plan how to orchestrate jobs.
- Define K8s resources needed: Mounting configmaps, volumes, set anti-affinity, nodeSelectors, etc.
- CRD not needed: A Kubernetes custom resource is not needed.
### Spark Operator The SparkOperator project was developed by Google and is now an open-source project. It uses Kubernetes Custom Resource for specifying, running and surfacing the status of Spark Applications. Some nice features include:
- Declarative: Application specification and management of application through custom resources.
- Planned restarts: Configurable restart policy.
- K8s resources automatically defined: Support mounting configmaps and volumes, set pod affinity, etc.
- Dependencies injection: Inject dependencies directly.
- Metrics: Supports collecting and exporting application-level metrics and driver/executor metrics to Prometheus.
- Open-source community: Everyone can contribute.
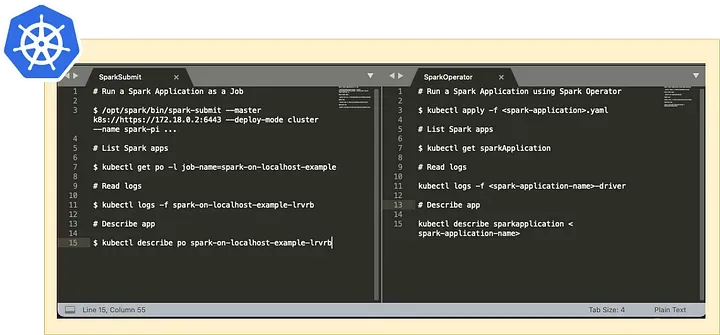
The image above shows the main commands of Spark Submit vs Spark Operator.
Empathy’s solution prefers Spark Operator because it allows for faster iterations than Spark Submit, where you have to create custom Kubernetes manifests for each use case.
## Solution Details To solve the questions posed in the Challenges section, ArgoCD and Argo Workflows can help you, along with the support of CNCF projects. For instance, you can schedule your favourite Spark Applications workloads from Kubernetes using ArgoCD to create Argo Workflows and define sequential jobs.
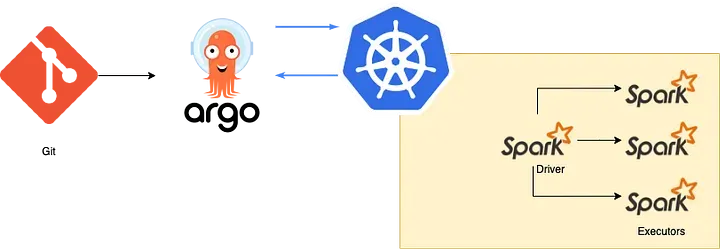
The flowchart would be as follows:
- Define your changes on git.
- ArgoCD syncs your git changes to your K8s cluster (for instance, create an Argo Workflow template).
- Argo Workflows template allows you to customise inputs and reuse configurations for multiple Spark jobs and create nightly jobs based on Argo Workflows.
### ArgoCD ArgoCD is a GitOps continuous delivery tool for Kubernetes. The main benefits are:
- GitOps: Using git repositories as a source of truth for defining the desired application state.
- Declarative setup: Everything on git!
- Traceability and automation: Apps deployments can track updates to branches, tags, etc. Apps deployment will be automated based on the specific target environments.
- Web UI: Good-looking UI to check the workloads deployed.
- K8s manifests: Kustomize, Helm, ksonnet, jsonnet, etc. Choose your fighter! More detailed information can be found in their official documentation.
### Argo Workflows Argo Workflows is a workflow solution for Kubernetes. The main benefits are:
- Job orchestration: Allows for orchestrating jobs sequentially or creating a custom DAG.
- Schedule workflows: Cron native.
- Spark Applications: Easily orchestrate Spark Applications on any Kubernetes cluster.
- Workflow Template: Reuse templates for different use cases. Input can be parameterised.
- WebUI: Great visual UI to check the workflows’ progress. More detailed information can be found in their official documentation.
### Monitoring Once Prometheus scrapes the metrics, some Grafana Dashboards are needed. The custom Grafana Dashboards for Apache Spark are based on the following community dashboards:
- ArgoCD Dashboard
- Argo Workflow Dashboard
- Apache Spark Operator Dashboard
- Apache Spark Applications Dashboard
To sum up
Empathy chooses Spark Operator, ArgoCD and Argo Workflows to create a Spark Application Workflow solution on Kubernetes and uses GitOps to propagate the changes. The setup illustrated in this article has been used in production environments for about one month, and the feedback is great! Everyone is happy with the workflow — having a single workflow that’s valid for any cloud provider, thus getting rid of individual cloud provider solutions.
To test it for yourself, follow these hands-on samples and enjoy deploying some Spark Applications from localhost, with all the setup described in this guide: Hands-on Empathy Repo.
I’ve also drawn upon my presentation for Kubernetes Days Spain 2021.
Though the journey was long, we’ve learned a lot along the way. I hope our innovations will help you become more cloud-agnostic too.
## References
- Spark Operator
- Running Spark on Kuberneteshttps://spark.apache.org/docs/latest/running-on-kubernetes.html()
- Implementing and Integrating Argo Workflow and Spark on Kubernetes
- Argo Project
- Scaling Apache Spark on Kubernetes
- Spark Docker Image
- Optimising Spark Performance on Kubernetes
- Spark on Kubernetes with Argo and Helm — GoDataDriven
- Amazon EKS Spark ETL Workloads
- Migrating Spark Workloads from EMR to K8s
- Hands-on Empathy Repo: Spark on Kubernetes
About the Author
I'm a Platform Engineer Architect specializing in cloud-native technologies and engineering leadership. With extensive experience in both Apache Spark and Kubernetes, I focus on building scalable, cloud-agnostic data processing solutions.


